03:00
How to publish FAIR research outputs
The Alan Turing Institute
Hi, I’m Eirini 👋

Eirini Zormpa, Community Manager Open Collaboration @ AIM RSF
AI for Multiple Long-term Conditions Research Support Facility (AIM RSF)

Hi, I’m Eirini 👋
Eirini Zormpa, Community Manager Open Collaboration @ AIM RSF
Previously:
- Trainer on Research Data Management & Open Science @ Delft University of Technology 💻
- Doctoral Researcher @ Max Planck Institute for Psycholinguistics 🧠
Example

Evelina Gabasova, Principal Research Data Scientist
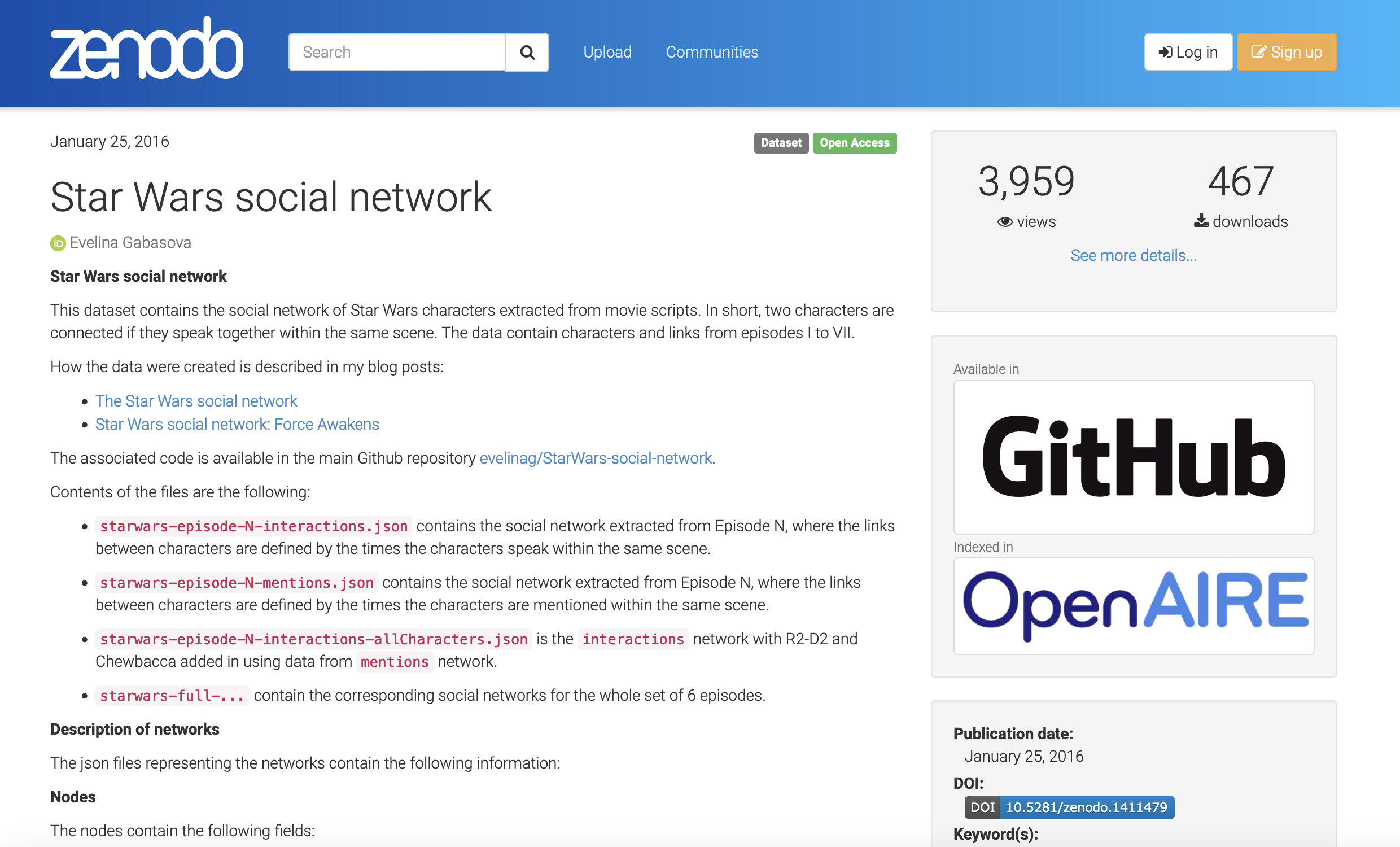
Why share all these other outputs?

The FAIR principles

Findable: Persistent identifiers 🔍
Outputs should also be assigned a unique and persistent identifier, e.g. a Digital Object Identifier (DOI). This makes it easy to find outputs, but also to link them with other relevant information (e.g. a publication).

Findable: Persistent identifiers for people 🔍
Persistent identifiers for researchers help if you have a common name or if you change your name!

Dates
To avoid ambiguity, use the RFC3339 standard: YYYYMMDD.

Example of a README file
Licence example

Creative Commons (CC) licences

OSI-approved licences for code


How to find repositories?

Data
Protocols
Zenodo
Zenodo is an open repository that accepts most research outputs.
- ✅ Funded by CERN, OpenAIRE, and the European Commission.
- ✅ Built on open source infrastructure.
- ✅ Offers integration with GitHub to archive code.

Picking a repository

Example of a data paper
Example of a software paper
Thank you!

References (continued)
- Lin, D., Crabtree, J., Dillo, I. et al. The TRUST Principles for digital repositories. Sci Data 7, 144 (2020). https://doi.org/10.1038/s41597-020-0486-7.
- Silvester, N., B. Alako, C. Amid, et al. (2015). Content discovery and retrieval services at the European Nucleotide Archive. Vol. 43 , pp. D23-D29. DOI: 10.1093/nar/gku1129.
- The Turing Way Community, & Scriberia. (2023). Illustrations from The Turing Way: Shared under CC-BY 4.0 for reuse. Zenodo. https://doi.org/10.5281/zenodo.7587336.
- Wilkinson, M., Dumontier, M., Aalbersberg, I. et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci Data 3, 160018 (2016). https://doi.org/10.1038/sdata.2016.18